Pix To Pixel: Image-to-image translation with a conditional GAN
Pixel to Pixel: a practical introduction
MACHINE LEARNING
3/6/20236 min read
What is Pixel to Pixel?
Pix to Pix, also known as image-to-image translation, is a machine learning technique that uses GANs (Generative Adversarial Networks) to transform images from one domain to another. It has practical applications in several fields such as computer vision, robotics and more.
Let's consider a specific example: suppose we have already isolated the eye region from a facial image using a tool like Mediapipe (here is an article about it), and we want to make modifications to this image, such as adding or removing glasses, changing the eye colour, adding makeup or similar transformations. To do that we would need to follow the following steps:
Collect images with and without the transformation applied (for instance, the same person with or without makeup, with or without glasses)
If the images do not contain just the eye region, you might want to crop them, using Mediapipe (It's worth noting that cropping the images using Mediapipe is an optional step, but it may improve the accuracy and performance of the model, particularly if the eye region is small or difficult to isolate from the rest of the image.).
Train a Pix-to-Pix model where the image without transformation is going to be the input and the image with the transformation is going to be the desired output.
Then at the inference phase, repeat step 2 (if done at training time), and provide the model with an input image.
How does it work internally?
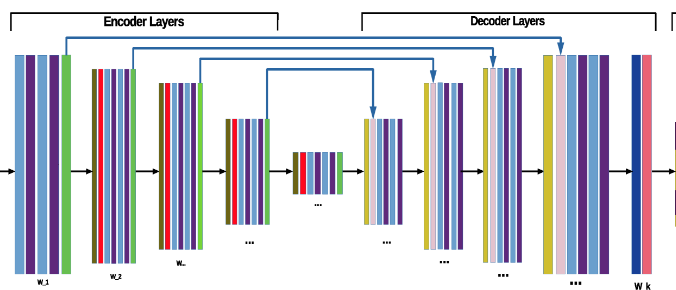
Pix to Pix works by using a neural network architecture called a UNET to generate output images from input images, based on a set of paired image data used for training. The UNET consists of an encoder network that captures high-level features from the input image, followed by a decoder network that generates the corresponding output image based on those features. During training, the UNET is paired with a discriminator network, which is responsible for distinguishing between real and fake images. The discriminator network is trained to identify the differences between the output images generated by the UNET and the corresponding real images in the training set. The UNET is trained to minimize the difference between its generated output images and the corresponding real images, while the discriminator is trained to maximize the difference between the two. Together, the UNET and discriminator work to improve the quality and realism of the generated output images, resulting in a powerful image-to-image translation model.
UNET (the generator)
Let's have a look at what the UNET looks like: (URL original image)
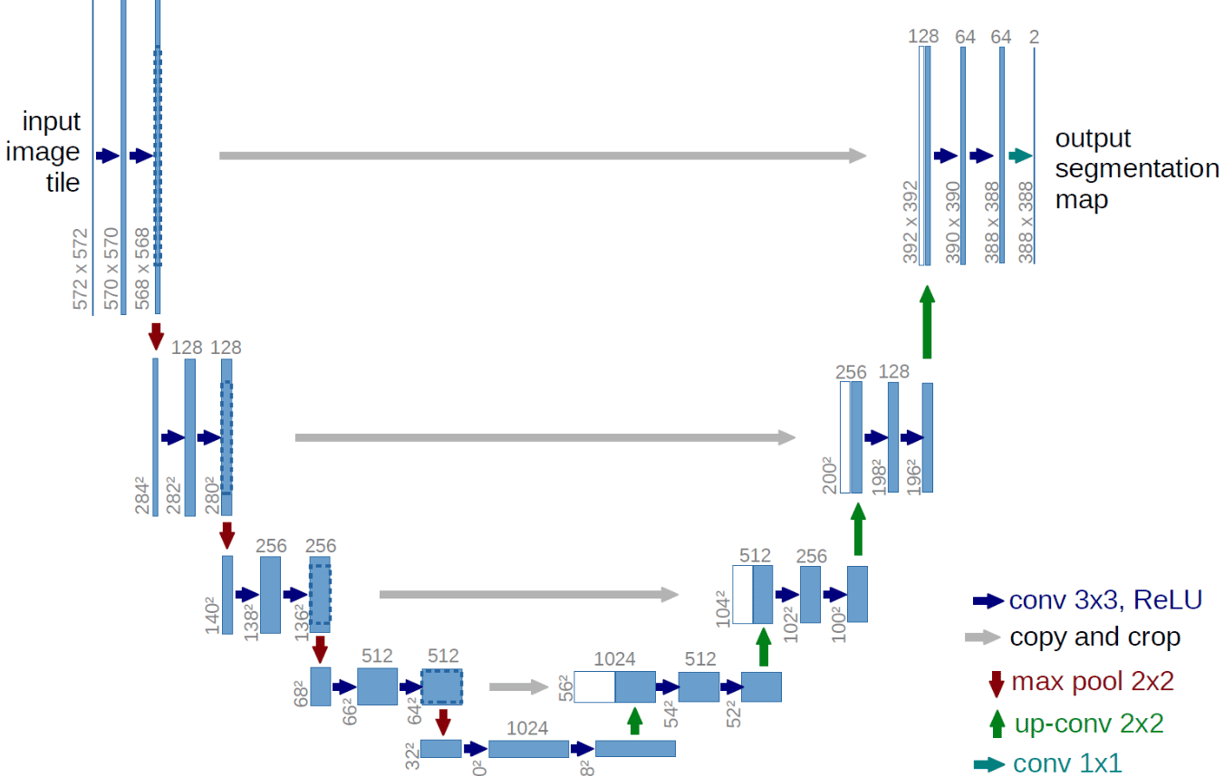
The UNET consists of two parts: an encoder network and a decoder network. The encoder network takes in the input image and passes it through several convolutional layers that extract high-level features. The output of each convolutional layer is fed into a downsampling layer that reduces the size of the image representation. The decoder network then takes the compressed representation generated by the encoder network and passes it through several deconvolutional layers that gradually increase the resolution of the image. Each deconvolutional layer is followed by an upsampling layer that increases the size of the image representation. The final output of the decoder network is an image that has the desired characteristics, based on the input image and the specific task being performed. During training, the UNET is optimized to minimize the difference between its generated output images and the corresponding real images in the training set, using a loss function like Mean Squared Error (MSE) or Binary Cross-Entropy (BCE). By using a UNET, Pix to Pix can generate highly realistic output images that closely match the characteristics of the corresponding real images, making it a powerful tool for image-to-image translation. In other words, the original image (probably normalized), passes through several CONV2d layers first, getting smaller and smaller, after a certain number of CONV2d layers (encoder) it gets upsampled again through CONV2d transpose layers, reaching back to the original size. From the diagram above, it is also easy to see how some of the CONV2d layers are passed through (grey arrows) to the decoder, this is done because like that more information is passed through making the task easier to learn. It may seem complicated at first, but at its core, it simply distils information from the input image in the encoder phase and then reconstructs it back into an output image in the decoder phase. The skipped connections (grey arrows) between corresponding layers in the encoder and decoder networks play a crucial role in ensuring that the network can capture both local and global features of the input image. These connections help to preserve high-resolution details and reduce the risk of information loss during the downsampling process. This is how it could look like in Python:
The bottleneck part is the "linker" between the encoder and the decoder.
Potentially you can use the UNET for segmentation tasks or "pixel to pixel" tasks, without even using the discriminator, but in theory, the discriminator should help the overall training. Let's have a look at it in the next paragraph.
The discriminator
The discriminator network is a critical component of the larger GAN architecture, which consists of a generator network (the UNET) and a discriminator network. The discriminator network is responsible for distinguishing between real and fake images, and it works by analyzing the features of the input image and making a classification decision. During training, the discriminator network is paired with the generator network, and the two networks are trained together in a competitive process. The generator network tries to generate images that can fool the discriminator, while the discriminator network tries to distinguish between the real images from the training set and the fake images generated by the generator. By using this adversarial training process, the discriminator network is able to learn to identify the subtle differences between real and fake images, and the generator network is able to learn which features of the input images are most important for generating realistic output images.
When the generator network produces a fake image, the discriminator network evaluates the image and calculates a loss function based on its ability to correctly classify the image as either real or fake. This loss function reflects how well the generator is performing at creating images that resemble real images. The generator network then uses this feedback to update its weights so that it can improve its ability to generate more realistic images in future iterations of training. This feedback loop is a crucial part of the Pix to Pix training process, as it allows the generator to learn from the discriminator's evaluations and improve over time. In particular, the generator network is trained to generate images that can "trick" the discriminator into thinking that they are real, by minimizing the discriminator's ability to distinguish between real and fake images. This is achieved by optimizing the generator's weights to minimize the combined loss function, which includes both the difference between the generated output images and the real images, as well as the discriminator loss. By using the discriminator loss to train the generator, the Pix to Pix model is able to create output images that are highly realistic and closely match the characteristics of the corresponding real images. Overall, the training process of the Pix to Pix model is iterative and dynamic, with the generator and discriminator networks working together to improve the quality of the generated output images. To understand the fact that the generator loss is formed by the generator loss itself, plus the discriminator loss look at the following code (taken by the official PixToPix TF tutorial):
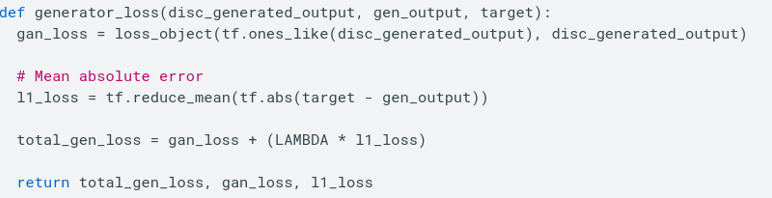

The l1_loss is the actual generator loss, the gan_loss is the discriminator loss, LAMBDA is a parameter to give more weight to the l1_loss itself, but you can tune it (by default is 100).
Wrapping up, plus a link to the complete code
Pix to Pix is a powerful but complex image-to-image translation model that can generate highly realistic output images. However, its architecture and training process can be difficult to understand and require significant computing power and expertise. Nevertheless, Pix to Pix is a valuable tool for researchers and practitioners in a variety of fields seeking to push the boundaries of computer vision.
Here you can find a working version, by which you can start experimenting with this kind of GAN. You can use the gan.py file to get started, just setting the right input image size, as well as the number of channels (1 for grayscale, and 3 for RGB images).
e.durso@ed7.engineering
Headquartered in Milan, Italy, with a strong presence in London and the ability to travel globally, I offer engineering services for clients around the world. Whether working remotely or on-site, my focus is on delivering exceptional results and exceeding expectations.