How to use OpenAi and Langchain to create a QA bot
Let's understand how to use use OpenAI and Langchain to create a powerful bot
MACHINE LEARNING
7/18/20236 min read


In today's digital landscape, businesses are constantly seeking innovative solutions to enhance customer engagement and improve internal processes. One such solution that has gained immense popularity is the chatbot—an intelligent virtual assistant that uses AI and natural language processing to engage in human-like conversations. Chatbots have revolutionized customer experiences by providing personalized support, reducing response times, and ensuring consistent and accurate information delivery. They excel at handling a wide range of queries, from product inquiries to issue resolution, thereby enabling businesses to provide exceptional customer service effortlessly. Beyond customer interactions, chatbots play a pivotal role in internal knowledge management. Maintaining an organized knowledge base is often challenging for growing organizations. By integrating a chatbot with internal documentation, companies can create a centralized and intelligent system that employees can rely on for instant access to critical information. This saves time, fosters consistency, and enhances productivity.
The main concepts
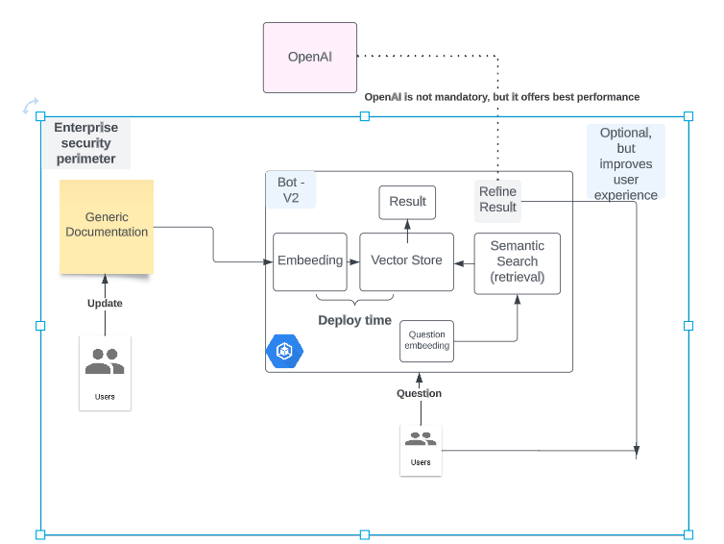
There are several approaches to building chatbots, and in this article, we will focus on embedding for knowledge retrieval combined with LLM (Language Model) refinement using OpenAI technology. This powerful combination leverages pre-trained language models to retrieve relevant knowledge and then refines the responses for improved accuracy and contextual understanding. However, it's important to note that similar results can also be achieved using pure open-source models, depending on the specific needs and resources of the organization. Let's have a look at an high level diagram:
We have the following essential blocks:
The documentation undergoes the "embedding" process, which involves transforming sentences into numerical vectors. This approach goes beyond relying solely on syntax, as seen in methods like TF-IDF, and instead leverages the semantic closeness of words and phrases.
The embedding artefact can be now stored in a vector store for easy retrieval. Please note that this step and the previous step need to be done when the documentation is updated.
When a user asks a question, the answer itself needs to pass through the embedding process (as the documentation) and then some documents can be retrieved using any distance metric. For instance cosine distance.
Please note that given the above step, we have already achieved a good result, i.e.: retrieving documents that can help the users to answer the question.
To go one step further, we can now use an LLM (Large language model) to provide the user question as well as the context retrieved in the step above.
We can now provide the user with the LLM answer as well as the documents we retrieved.
Throughout the remainder of this article, we will strive to provide further clarity and offer practical, hands-on guides to help you navigate the topic at hand.
What is embedding
In the realm of natural language processing and machine learning, embedding techniques have played a significant role in revolutionizing language understanding and representation. One landmark advancement in this field came with the introduction of word2vec, a popular and influential algorithm developed by Tomas Mikolov et al. at Google in 2013. Word2vec paved the way for modern embedding methodologies, allowing words to be represented as dense, continuous vectors in a high-dimensional space. This breakthrough opened doors to capturing semantic relationships and contextual nuances within language, fundamentally transforming how we approach tasks like information retrieval, sentiment analysis, and machine translation.
Word2vec operates on the principle that words that frequently co-occur in similar contexts are likely to have similar meanings. It offers two main algorithms for training word embeddings: Continuous Bag-of-Words (CBOW) and Skip-gram. In the CBOW approach, the model predicts the target word based on its surrounding context words. It tries to maximize the likelihood of the target word given the context words, learning to associate words that appear in similar contexts. The Skip-gram approach is the reverse of CBOW. It predicts the context words based on a given target word. This method allows the model to capture more detailed information about the relationships between words. Both CBOW and Skip-gram use a neural network architecture with a single hidden layer. The network is trained on a large corpus of text data, and during training, the weights of the hidden layer are adjusted to minimize the prediction error. The trained word2vec model generates word embeddings as a result of this training process. These embeddings are dense vector representations, where words with similar meanings or semantic relationships are closer to each other in the embedding space. The embeddings capture various linguistic properties, such as analogies, relationships, and contextual similarities.
While word2vec is a popular and influential algorithm for learning word embeddings, it's important to note that there are other approaches and models available in the field of NLP. Embeddings can also be computed using methods such as GloVe (Global Vectors for Word Representation), fastText, ELMo (Embeddings from Language Models), and more. Each method may have its own unique characteristics and advantages, but the explanation provided above should suffice to grasp the fundamental concept of word embeddings and their significance in language understanding. These embedding techniques have been instrumental in advancing various NLP applications and continue to be an active area of research and innovation.
Make your life easier with Langchain
Langchain is a Python package that allows you to build applications with large language models (LLMs) through composability. It provides a simple and intuitive API that makes it easy to use LLMs for a variety of tasks, such as text generation, translation, and question-answering. Langchain is open source and available on GitHub.
Here are some of the features of Langchain:
Simple and intuitive API: Langchain provides a simple and intuitive API that makes it easy to use LLMs for a variety of tasks.
Flexible and composable: Langchain is flexible and composable, which means that you can easily combine different LLMs and tasks to create powerful applications.
Extensible: Langchain is extensible, which means that you can easily add new features and functionality.
Open source: Langchain is open source, which means that it is free to use and modify.
Langchain makes the building blocks above very easy to manage and modify.
As said before, Langchain is flexible, so it supports several embedding methods as well as several LLM models. To get started with OpenAI, you need to create an OpenAI API Key, and set it like this:
The first thing to do is to 'embed' the documentation itself, Langchain is flexible and it supports several file formats. You can load PDFs/CSV/JSON/Markdown ecc. Following an example for Markdown:
Now, after having loaded the Markdown files, we can create the embedding and store into a store, example:
as you can see, creating the embedding is literally just a line of code, which is exactly one of the LangChain strengths, it hides all the complexity. To store the results, we are using Chroma, but LangChain supports several more vector stores.
It is important to notice, that after this step, we can already start retrieving information. In other words, we are already able to retrieve documents given a question (without any LLM refinement):
this will return K documents that match the user question. So potentially, you can stop here, and return those documents. There is already some value, but we can do better with LLM refinement. To do that, we need to instantiate an LLM model, which in the case of OpenAI is just:
Now we need to prepare the template, which is as easy as:
The layout given is self-evident; the intriguing aspect is its usage of 'context' and 'question'. The 'context' is drawn from the Embedding phase, while the 'question' is essentially the query posed by the user. Then finally we can call the LLM like this:
As evident, there's no need for us to manually invoke the Language Model (LLM), thanks to Langchain which simplifies the process by leveraging the 'chain' concept. It seamlessly integrates the outcomes from the retriever with the LLM, providing a smooth and meaningful interaction. Also, you can print the result (output from LLM itself) as well as the documents that have been used to generate the context. You can pass both back to the user for a great experience.
Conclusion
This article provides a comprehensive exploration of chatbot technology, focusing on the impactful role of OpenAI's language models and the importance of 'embedding' in semantic understanding. Through practical examples, the efficacy and application of these sophisticated models in creating dynamic, interactive chatbots are demonstrated. Furthermore, the article introduces Langchain, a Python package designed to simplify development work with language models, presenting its utility and how it streamlines the process.
e.durso@ed7.engineering
Headquartered in Milan, Italy, with a strong presence in London and the ability to travel globally, I offer engineering services for clients around the world. Whether working remotely or on-site, my focus is on delivering exceptional results and exceeding expectations.