How to run inference with LamaV2 chat in your local machine
A quick introduction to the LamaV2 inference process
MACHINE LEARNING
9/20/20233 min read


Introduction
In the ever-evolving landscape of Natural Language Processing (NLP), the constant pursuit of excellence has brought us transformative technologies that continue to break new ground. If you've been following this thrilling journey, then prepare to be astounded yet again—Meta has just released LamaV2, a highly advanced Language Model (LLM) that promises to be a game-changer in the field. Following up on its predecessor, Llama 1, the latest release offers an impressive lineup of pre-trained and fine-tuned models with a staggering scale of 7B to 70B parameters. But that's not all. LamaV2 arrives with an arsenal of features that dramatically enhances its performance: 40% more training tokens, a whopping 4k context length, and cutting-edge grouped-query attention mechanisms for blazing-fast inference on its most colossal 70B model. This is not just a step but a giant leap forward in machine understanding of human language. With such robust capabilities, LamaV2 is set to redefine what we think is possible in applications ranging from chatbots and content generators to complex data analytics and beyond. In this blog post we are going to cover how to run inference with LamaV2 in your local machine, training and fine-tuning will be covered in the next article.
How to get model access
Step 1: Register on Meta's Official Site
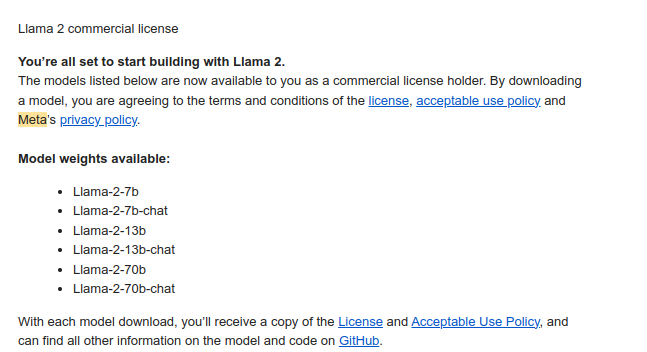
Firstly, head over to Meta's Lama Downloads page. You'll find a module that you need to fill in. Don't worry; approval is usually almost instantaneous. Shortly after you complete the registration, you'll receive a confirmation email. Make sure to keep an eye on your inbox to see an email similar to:
Step 2: Create a HuggingFace Account
If you don't already have an account with HuggingFace, now's the time to make one. Sign up here, and crucially, use the same email address you registered with on Meta's site. This is essential for the subsequent steps.
Step 3: Request Model Access on HuggingFace
Now, navigate to Meta's official Lama 2 repository on HuggingFace. Select the model you're interested in, such as meta-llama/Llama-2–7b-chat-hf. Another form will appear that you'll need to fill out. Again, it's essential to use the same email address that you've been using for previous registrations.
A Word on Timing
While Meta generally grants immediate access, acquiring permissions through HuggingFace can take a bit longer—up to 10 days. So, exercise a little patience; it'll be well worth the wait!
Getting the environment ready
Ok, now it's coding time!
Feel free to use the IDE you prefer or a Jupyter Notebook for this section. First of all, there are some dependencies to be installed in your Python environment:
You also need to authenticate to HuggingFace:
If you don't have a token yet, you can create it here
How to prompt the model
One often-overlooked benefit of open-source language models is the ability to fully customize the system prompt within chat-based applications. This customization is key for defining your chatbot's behavior and even giving it a unique personality—something that's not achievable with models that are solely accessible via APIs.
The initial turn's prompt template appears as follows:
<s>[INST] <<SYS>>
{{ system_prompt }}
<</SYS>>
{{ user_message }} [/INST]
This formatting adheres to the model's original training regimen, which is outlined in the LamaV2 academic paper. While you're free to insert any system prompt you desire, it's imperative that the format aligns with that used during the model's training.
Let's have a look at an example:
This is the prompt (note <s>, which I have to remove from the above snippet, as it was causing issue when showing):
<s>[INST] <<SYS>>
As a professional Machine Learning engineer, help the user kindly <</SYS>>
What is LamaV2 (Meta) ?
[/INST]


This is the response
Not too bad, you can also try the same with the 13B and the 70B, if you have enough resource!
e.durso@ed7.engineering
Headquartered in Milan, Italy, with a strong presence in London and the ability to travel globally, I offer engineering services for clients around the world. Whether working remotely or on-site, my focus is on delivering exceptional results and exceeding expectations.